If you have a list of items and want to remove any duplicate entries in the list, here are three great ways to go about it.
Watch on YouTube & Subscribe to our Channel

1. The Remove Duplicates Button on the Data Tab
Firstly, if you go to the Data tab on the Ribbon, there's a button called Remove Duplicates.
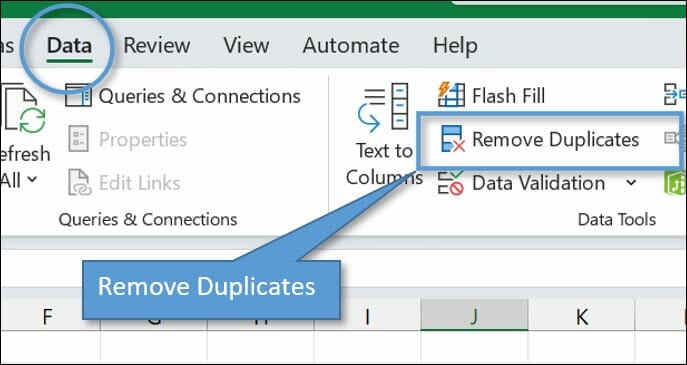
With any cell selected in the column that you want to remove duplicates from, just hit the button. Then you'll get a Remove Duplicates popup window to verify which columns you want to change. Verify your selection and hit OK.
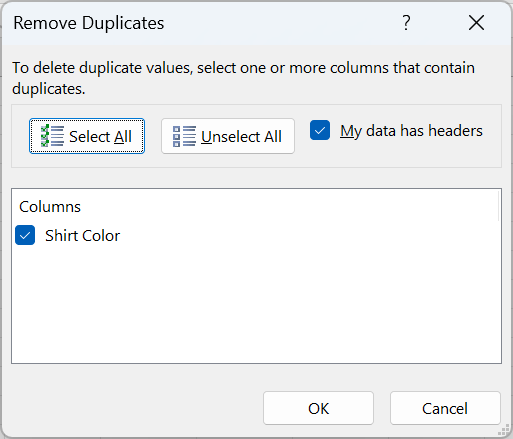
If you want to keep the original list, make a copy before removing the duplicates.
2. The UNIQUE Function
The UNIQUE function has options to de-duplicate columns OR rows. Also, it has the ability to return values that only appear once in the list.
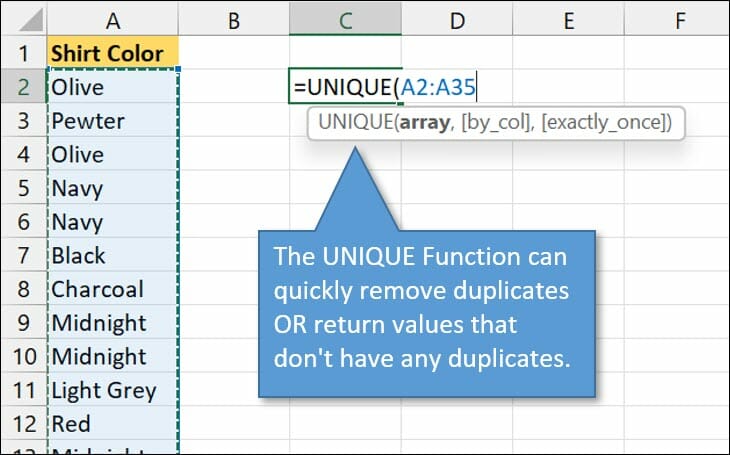
You can even use the UNIQUE Formula for Non-Adjacent Columns.
3. Power Query
Power Query has the ability to remove duplicates in one or more columns.
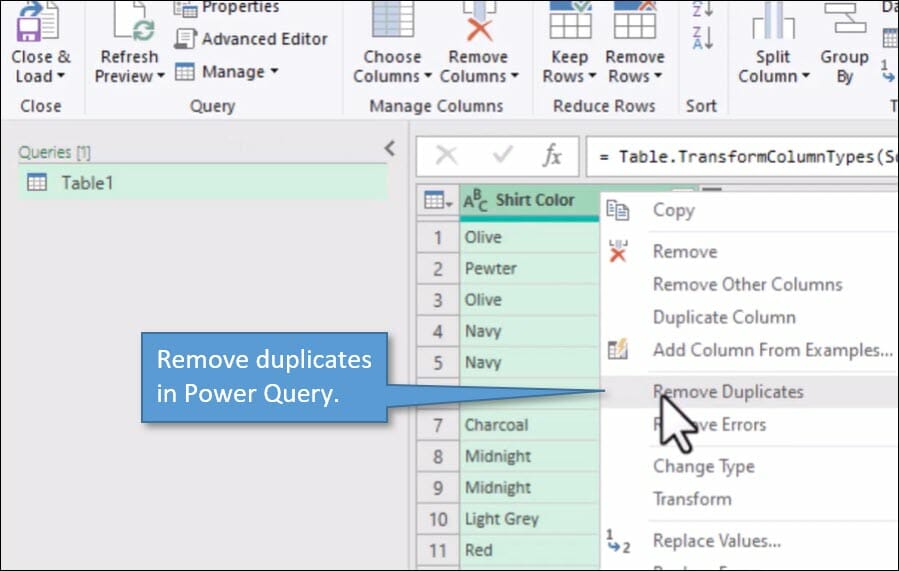
If you're not familiar with Power Query, it's a powerful data automation tool, and it's great to use for importing data into Excel and cleaning it up. You can learn more about Power Query at this tutorial: Power Query Overview: An Introduction to Excel’s Most Powerful Data Tool
Other Methods?
So, how do you de-dupe? Leave a comment if there are other techniques that I missed.
Hope this was helpful! See you again next time.



Pivot table
You could also use a pivot table.
You did miss out on the most manual way to remove duplicates (Which was my main means to do so for a long time…).
Using the conditional formatting to highlight duplicates, and then manually delete them from the sheet. The fact that this is such a manual process is probably why you omitted it from the post, but it is another option…
thank you,
I love the unique(table[column]) to automate spreadsheets. I just wish there would be a way to insert such function in another table without getting the #spill, but i go around it by adding the formula in a hidden column + linking my table to such column. Any better ideas ?
Thanks !
Alex
Going to Excel’s 15 digits of precision, do any of these dedupe methods have the protential to remove nonduplicates if the numbers are too long?
I wrote a macro about 20 years ago that will flag duplicates (in case I want to inspect the other fields in the record to determine which dupe to keep or delete.
Sub FlagDuplicateRows()
‘highlights duplicate records
‘
Dim HighlightCount, Msg, Style, Title, Help, Ctxt, Response, MyString
HighlightCount = 0
Selection.EntireColumn.Insert
ActiveCell.Offset(0, 1).Range(“A1”).Select
Do Until ActiveCell.Value = “”
If ActiveCell.Offset(1, 0).Value = ActiveCell.Value Then
ActiveCell.Offset(0, -1).Value = “x”
ActiveCell.Offset(1, -1).Value = “x”
HighlightCount = HighlightCount + 1
Else
End If
ActiveCell.Offset(1, 0).Range(“a1″).Select
Loop
‘display message box indicating the number of rows deleted
Msg = HighlightCount & ” Rows highlighted”
Style = vbOKOnly
Title = “Highlight Rows Complete”
Help = “DEMO.HLP” ‘ dummy Help file.
Ctxt = 1000
Response = MsgBox(Msg, Style, Title, Help, Ctxt)
End Sub
At my job we only wanted to detect duplicates, not remove them. So we created a COUNTIF column and counted how many times each ID# existed within the entire column of ID#s. If the number was 1, then the ID# existed only 1 time and it could not be a duplicate. If the number was 2 or more then it was worth researching further into.
Thanks for sharing these helpful tips! I’ve always struggled with duplicate entries in my spreadsheets, so I’m excited to try these methods. The detailed explanations and screenshots make it easy to follow. Can’t wait to clean up my data!
Great tips! I especially appreciated the shortcut method for quickly removing duplicates. It’s always frustrating when you find duplicate entries in your data, and these strategies will definitely save me a lot of time. Thanks for sharing!
Great tips! I found the methods easy to follow and super helpful for cleaning up my data. Thanks for sharing!
Great tips! I never knew about the unique function for removing duplicates—it’ll definitely save me a lot of time. Thank you for sharing these methods!
Great tips! I especially found the Power Query method really useful for handling large datasets. Thanks for sharing these insights!